
Supere los desafíos del análisis celular de alto contenido mediante la IA y el aprendizaje automático
La inteligencia artificial (IA) encuentra ocupa ya un lugar en muchos aspectos de la vida moderna, desde vehículos autónomos a asistentes personales activados por voz, e incluso en la creación de arte. Pero es la aplicación en la ciencia y la atención médica donde realmente se destacan los beneficios de la AI. Una de estas aplicaciones se encuentra en el análisis de bioimagen o en el análisis de alto contenido (HCA).
A medida que HCA ha llegado a la maduración y ha adquirido una mayor adopción como herramienta cuantitativa para la investigación biomédica, el espacio de aplicación sigue aumentando y ya no se limita a una lista finita de ensayos bien definidos realizados en modelos biológicos estándar. Para tener en cuenta esta mayor complejidad, se ha centrado mucho en mejorar la flexibilidad y el rendimiento de los métodos de análisis a través de la AI o el aprendizaje automático. De hecho, hay muchos ejemplos en los que supera a los métodos tradicionales para aplicaciones en muchas disciplinas científicas.
Hasta hace poco, el uso de estos métodos de aprendizaje automático más complejos se ha reservado en gran medida a grupos de investigación que tienen acceso adecuado a habilidades especializadas en ciencia de datos y desarrollo de software personalizado. Aquí, ofrecemos una breve introducción a la AI y analizamos cómo las soluciones de software de aprendizaje automático llave en mano emergentes están permitiendo a los investigadores aprovechar todo el contenido de una imagen y realizar un análisis más completo, al tiempo que eliminan la carga de la complejidad para el usuario.
¿Qué es la AI o el aprendizaje automático?
El aprendizaje automático es una forma de AI (inteligencia artificial). Aprendizaje profundo. Redes nerviosas. Todos estos son términos ligeramente diferentes para la AI, que el diccionario de Oxford define como:
“La teoría y el desarrollo de sistemas informáticos capaces de realizar tareas que normalmente requieren inteligencia humana, como la percepción visual, el reconocimiento del discurso, la toma de decisiones y la traducción entre idiomas”.
Básicamente, la AI representa cualquier información que se pueda demostrar mediante máquinas que imitan funciones cognitivas que normalmente asociaríamos con mentes humanas como el aprendizaje, la resolución de problemas y el razonamiento. El aprendizaje automático es una técnica utilizada por los científicos para permitir que los ordenadores aprendan rápidamente de los datos.
Superar las complejidades de un flujo de trabajo HCA
En su núcleo, una selección de alto contenido o un flujo de trabajo HCA, como nuestro ImageXpress Confocal HT.ai más que una microscopia automática seguida de un análisis de imágenes automático. Durante la fase de adquisición, las imágenes se adquieren de múltiples muestras en placas de microtitulación. Esto puede implicar recopilar una gran cantidad de datos de imágenes si está tratando de comprender, por ejemplo, un fármaco eficaz para rescatar algunos fenotipos afectados.
La parte de análisis del flujo de trabajo se puede dividir en dos partes: análisis de imágenes y análisis descendente. Durante el análisis de imágenes, determinadas características y mediciones se extraen de la imagen y se convierten a un formato en el que se puede aplicar el análisis estadístico. El análisis descendente implica tomar todos los datos dimensionales altos y destilarlos hasta un formato que los científicos puedan interpretar y extraer conclusiones para que puedan continuar con la siguiente fase de su proyecto de investigación.
El mundo actual de la detección de alto contenido es mucho más integral cuando se trata de comprender y describir un fenotipo. En lugar de extraer una sola característica o tomar una relación de algunas mediciones diferentes, los investigadores están extrayendo miles de características para cada célula dentro de una imagen. Esto no requiere que sepan cuál es el objetivo de un fármaco o que comprendan completamente la función de un gen. Simplemente busca diferencias entre dos condiciones diferentes al aprovechar todo el contenido rico en información dentro de la imagen.
A medida que la complejidad de ciertos ensayos continúa aumentando y a medida que extraemos más información de una célula individual, los datos se vuelven aún más abrumadores. Entonces, ¿cómo podemos entender toda esta información y destilarla hasta algo que sea factible?
Los métodos tradicionales de análisis de imágenes pueden ser especialmente intrincados y requieren mucho tiempo cuando se realizan manual o semiautomáticamente. Siempre existe la posibilidad de error y prejuicios humanos debido a la naturaleza difícil y extremadamente detallada de la tarea. Cuando a esto se añade la naturaleza repetitiva, prolongada y a menudo laboriosa del flujo de trabajo, surge la oportunidad de aplicar el aprendizaje automático. La AI elimina cualquier variación de persona a persona, error humano y prejuicio, lo que mejora la calidad y la confianza de los datos, además de optimizar el flujo de trabajo y la eficiencia.
Superar los prejuicios humanos
Uno de los beneficios clave del aprendizaje automático en HCA que se merece una nota especial es la capacidad de superar los prejuicios humanos. Cuando se estudian grandes conjuntos de datos, los humanos son vulnerables a un fenómeno bien descrito denominado “ceguera accidental”. Aquí es donde las observaciones inesperadas pasan desapercibidas al realizar otras tareas que requieren atención.
Por ejemplo, después de haber estudiado previamente un determinado fenotipo y respuesta celulares en detalle, podría estar buscando accidentalmente esos mismos signos cuando se le presenta un conjunto de datos grande y complejo que contiene muchas variables y medidas. Al hacerlo, podría pasar por alto otra característica discreta o inesperada que también tiene importancia biológica.
El aprendizaje automático ayuda a superar esta vulnerabilidad, realizando una clasificación completamente sesgada, con el potencial de producir resultados inesperados y valiosos.
Aplicación del aprendizaje automático a la segmentación de objetos
Los datos cuantitativos fiables son cruciales para cada paso posterior en el flujo de trabajo de HCA, siendo la primera la segmentación. Segmentación es el proceso de extraer los objetos de interés (p. ej., orgánulos) de las imágenes y luego cuantificar sus características. Básicamente, es el primer paso para convertir píxeles de imagen en datos numéricos.
La segmentación puede ser difícil, especialmente cuando se trabaja con métodos de procesamiento de señal tradicionales, que están diseñados para centrarse en un objeto. En imágenes microscópicas de células o tejidos, los objetos suelen estar abarrotados o aglutinados. Además, tienen diferentes tamaños y formas. A menudo hay un problema de mala relación señal-ruido, bajo contraste y mala resolución de imagen. Por no hablar de esto, puede haber una alta variación fenotípica debido a las perturbaciones químicas o a la heterogeneidad natural en el propio tipo de célula.
Para abordar los problemas de la segmentación, se pueden aplicar algoritmos de aprendizaje profundo a la parte de análisis de imágenes del flujo de trabajo de HCA. Por ejemplo, el software de análisis de imágenes IN Carta l incluye un módulo basado en aprendizaje profundo llamado SINAP que está diseñado para funcionar con una amplia gama de datos.
Dado que SINAP utiliza aprendizaje profundo, puede tener en cuenta grandes cantidades de variación en la apariencia de la muestra que surgen de los tratamientos de prueba en investigación. Al garantizar que cada tratamiento se segmente con un nivel equivalente de precisión, la información extraída en este paso se puede utilizar de forma fiable para comparar los tratamientos en los pasos siguientes del análisis.
Ejemplos de módulo IN Carta SINAP en uso:
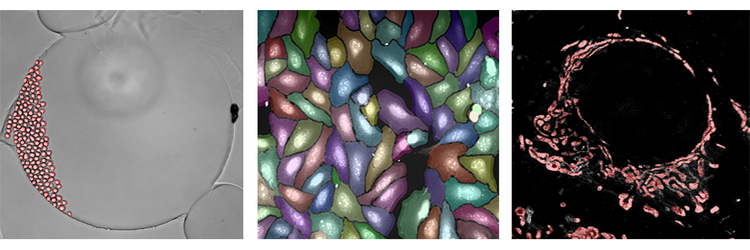
Arriba se muestran ejemplos del algoritmo de aprendizaje profundo SINAP que se aplica a tres conjuntos de datos completamente diferentes. El análisis de campo claro se muestra en la figura del extremo izquierdo. El análisis es en realidad una segmentación de célula única a lo largo del tiempo, observando cómo las células vivas se dividen y se mueven. La figura central muestra la segmentación de un análisis de pintura de celdas. Aunque las celdas están abarrotadas, SINAP puede segmentar los objetos con alta precisión. Por último, la figura del extremo derecho es de una imagen de superresolución de mitocondrias. Una vez más, aunque este contenido sea completamente diferente, se puede utilizar el mismo flujo de trabajo y algoritmo para estudiar las mitocondrias individuales en las fuentes de datos y la imagen. En los tres casos, podrá completar con más precisión y fiabilidad la segmentación con facilidad utilizando el algoritmo de aprendizaje profundo SINAP.
Aplicación del aprendizaje automático a la clasificación de objetos
Dado que está tratando de aprovechar tanto contenido como sea posible en un flujo de trabajo HCA, es importante asegurarse de que el contenido tenga algún grado de calidad antes de llegar al paso de análisis descendente. Aquí es donde entra en juego la clasificación de objetos. La clasificación de objetos es el proceso de división de conjuntos de datos en subpoblaciones en función del fenotipo (p. ej., morfología celular, localización subcelular, nivel de expresión de marcadores específicos).
Es posible utilizar una herramienta de clasificador para seleccionar manualmente características relevantes y asignar clases, pero esto solo es aplicable a los cambios fenotípicos sencillos basados en algunas medidas. Por ejemplo, podría estar determinando una etapa del ciclo celular en función de la intensidad de la aplicación de un tintura nuclear o clasificando las células vivas o muertas en un análisis de viabilidad. Para cualquier cosa más compleja que implique un conjunto ampliado de características, el uso de la AI para la clasificación de objetos se convierte en una opción mejor.
Con el aprendizaje automático, el usuario humano ya no tiene que seleccionar manualmente medidas o umbral. En su lugar, esta tarea se asigna al ordenador. El usuario humano proporciona ejemplos de ordenador de diferentes tipos de celdas. El ordenador averigua cómo diferenciar entre esas clases. Básicamente, el ordenador está aprendiendo las características más apropiadas y tiene la ventaja adicional de que puede aprender la combinación correcta de características.
El software IN Carta también incluye un módulo de clasificador de nivel de objeto formable llamado Phenoglyphs. El módulo Fenoglifos utiliza la información extraída por SINAP para agrupar objetos con una apariencia visual similar. Haciendo esto, se puede evaluar si un tratamiento genera un fenotipo favorable y se puede incluso inferir el mecanismo subyacente implicado. Usando el aprendizaje automático, se pueden analizar simultáneamente todas las características visuales para optimizar el conjunto complejo de reglas necesarias para asignar objetos al grupo correcto. Este enfoque altamente multivariable y basado en datos es mucho más capaz de resolver diferencias fenotípicas discretas y es más robusto contra la asignación de objetos al grupo incorrecto.
Los cuatro pasos de la formación del módulo IN Carta Phenoglyphs:
- Grupo: El módulo selecciona y utiliza automáticamente medidas calculadas durante la segmentación para crear agrupamientos naturales en los datos, denominados grupos, sin prejuicios humanos.
- Etiqueta: El usuario selecciona y etiqueta todas las clases válidas (al menos dos) para la clasificación y la formación.
- Clasificación: El módulo clasifica la lista de medidas utilizadas para dividir objetos en clases y proporciona la oportunidad de deseleccionar medidas con información redundante o poco impacto.
- Tren: El módulo refina el modelo de clasificación en función de la entrada del usuario, incluyendo la eliminación de objetos o la reasignación a clases más apropiadas.
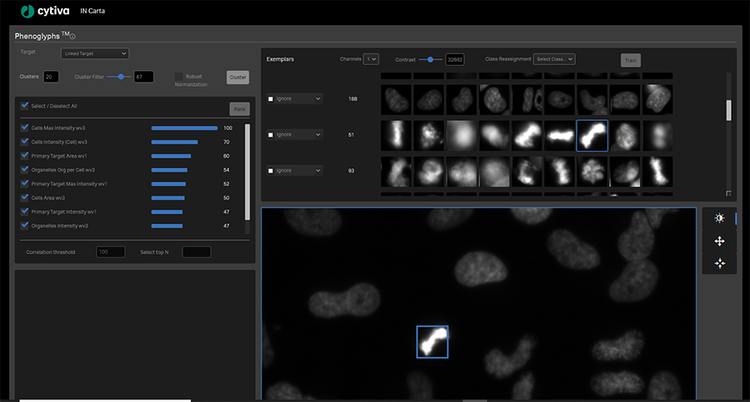
Formación del módulo de clasificación de aprendizaje automático Phenoglyphs
Como usuario, usted solo necesita revisar y proporcionar información sobre un número pequeño de ejemplos de cada clase antes de que el módulo Phenoglyphs aplique el modelo al conjunto completo de datos. Este enfoque reduce al mínimo la necesidad de entrada del usuario en el primer paso de asignación de clase, lo que ahorra un tiempo considerable.
Eliminación de las conjeturas
Exclusivo del software IN Carta es el paso inicial sin supervisar que está integrado en los módulos SINAP y Phenoglyphs. El paso no supervisado genera un resultado inicial que se optimiza de forma iterativa simplemente haciendo que el usuario confirme o corrija la decisión del algoritmo. Esto elimina la carga de determinar un punto de partida viable para el análisis y elimina la necesidad de ajustar los parámetros de una manera tediosa de prueba y error. Mediante la combinación de SINAP y Phenoglyphs, los usuarios experimentan un flujo de trabajo de extremo a extremo que no requiere experiencia previa en análisis de imágenes o estadísticas y se simplifica para reducir el tiempo de generación de resultados.
Obtenga más información sobre cómo optimizar su flujo de trabajo de HCA con aprendizaje automático. Consulta nuestra página del software IN Carta.